How Pepper builds AI agents that actually work at enterprise scale

The design principles behind Pepper’s 4-year record of AI success
AI agents look like magic, until they don’t. Too often, AI pilots stall as innovation experiments that never make it into day-to-day workflows. Large language models (LLMs) can hallucinate, miss steps, or create more work than they save. Gartner predicts over 40% of agentic AI projects will be scrapped by 2027, and other analysts have similarly dire prognoses; we’ve seen the same patterns in the market and in our clients’ internal AI programs.
Pepper’s job since the pre-ChatGPT era has been to drive AI projects from pilot to production. Over four years, we’ve learned how to build LLM agents that actually power dependable products and drive business value. We distilled that experience into Nymbus, our AI orchestration platform, and into a set of repeatable AI design practices. Below are some of the key lessons that matter when you build agentic AI for content and marketing.
1. Specialise and group your agents
Problem: LLMs have a narrow Goldilocks zone of specialisation.
LLMs aren’t good at over-broad or ill-defined tasks. They do best with clear directives and a tightly defined area of focus. Give an AI agent vague instructions, or ask it to pay attention to too many elements at once, and it will often flounder, offering inconsistent or misguided output and missing key information. As an example, if you instruct an agent to “plan and draft all blog content for a fintech client for the next month, it will tend to lose focus, mix tones, skip campaign priorities, and produce repetitive material. Designing AI agents for overly broad use scenarios also makes evaluation harder, as the goalpost is not clearly defined.
But over-specialising an LLM agent has its own risks. Narrowing an LLM’s scope too much can make it brittle. An agent primed or tuned for one narrow scenario often fails when the input changes slightly. You might see excellent results when the prompt matches the familiar pattern, and sudden performance drops the moment it doesn’t. For instance, an agent built only to generate five-point tip listicles for Gen Z readers might perform flawlessly on such briefs, but collapse when asked for an in-depth investment comparison piece for millennials.
What we do: We orchestrate many narrowly specialised agents.
At Pepper, we usually rely on clusters of agents, purpose-built for specific clients. Every agent has a clear, bounded brief, and they are all orchestrated within reliable workflows that control each agent’s operation and context.
A major Pepper client may require an assembly of a dozen agents that work together: an SEO researcher agent to analyse top competitor pages, a content planner agent using the SEO research to craft performance-optimised page outlines, a brand-tuned campaign brainstorm partner, a microcopy specialist for CTAs or headlines, various template-driven and free-form page creators, and so on. For a visa concierge client, we created a suite of research and content agents, each focused on a specific content cluster: a visa application researcher, photo requirement specialist, visa extension advisor, tourist guide, etc. Each agent used templates and data sources tailored to its cluster, which made scaling across hundreds of country pairs practical.”
There’s typically at least one such Pepper AI agent per client project, often one for every key stage of the project. If a single project has a lot of diverse subcategories or dimensions, we either create a group of smaller subagents or dynamically specialise a single master agent based on the user’s requirements (you’ll find an example of the latter in Image 1 below).
For highly creative-focused projects, Pepper’s human creators might get the option to select the right AI agent at their own discretion, like a toolkit. In other cases, where requirements are more predictable, our workflows programmatically route each task to the right agent. Multi-stage workflows may involve agents handing off tasks to one another, using structured schemas.
All of which begs the question: How can you possibly build that many agents? The answer is that our capabilities have compounded over time. We’ve accumulated several solid, repeatable AI methodologies. That and our massive reference library of tried-and-tested Pepper AI content apps, which range over a hugely diverse client portfolio, mean Pepper can quite rapidly put together and refine super-customised AI tools for most new projects.
Example: This WhatsApp Creative Builder flow on Nymbus dynamically specialises each agent’s capabilities for a single, well-defined job. When a user chooses a creative asset category (such as motivational messages, daily greetings, or festive wishes) and an asset type (image, reel, long-form video, etc.), the flow first identifies the right creative, localisation, video, subject, and category skills required. The Creative Planner agent is then selectively equipped with only those focused capabilities. Once planning is done, the workflow routes tasks to the right specialised image and video models, selected based on the required visual types. This way, every AI model used in the flow does exactly one thing, for which its abilities or context are specifically tailored.

Why this method works: Each AI agent sees a predictable input distribution and a narrow output spec. That makes behaviour more repeatable and testing easier to control. Every agent knows exactly what to produce and receives only what it’s designed to handle. Using a cluster of such specialised agents means the larger application can safely target a broader scope.
2. Combine AI with programmatic processing
Problem: AI is poor at deterministic tasks.
AI is not the right choice for every problem. LLMs are great at fuzzy, grey-area thinking: tasks that need nuance, interpretation, or creativity. But they’re not innately good at black-and-white logic, mathematical precision, strict recall, or rational decision-making.
That’s where many teams go wrong. They rely on AI for mechanical operations that traditional code can execute perfectly: checking conditions, finding and replacing values, counting sentence length, scoring readability, getting exact-match keyword frequency, and so on. Such tasks are better done the old-fashioned way.
What we do: We treat AI as one component of a hybrid mechanism.
We combine AI agents with deterministic workflows and programmatic steps. Scripts handle tasks LLMs aren’t naturally good at, like those mentioned above, plus verifying schemas, parsing and cleaning data, analysing files, running batch operations, transforming formats, catching error conditions, and more. Where logic must be exact, we rely on code. Where nuance matters, LLMs do the work.
Wherever a decision can be expressed deterministically – such as handling branching conditions, routing a task to the correct subagent, or selecting values based on user input – we do it with code, not with another model prompt.
Needless to say, Pepper’s AI agents are equipped with tool-calling abilities that let them run web searches, access web pages, read uploaded files, execute simple code, output structured objects, call internal Pepper functions, work with subagents, and so on. In workflows, our agents are specifically instructed to use programmatic methods wherever relevant.
Nymbus itself provides a library of programmatic steps: search the web, scrape pages, call services like Semrush, process files, fetch client knowledge-base assets, etc.
All these non-stochastic components act as guardrails around the creative core, keeping outputs consistent and reliable.
Example: Take the simple format handling step shown below. In this workflow, an LLM evaluates a written blog article against the original content brief (both generated by other Pepper AI subagents). Two programmatic steps surround the model call: one at the outset checks that the brief conforms to its expected schema; the other (shown expanded here) converts the model’s XML-tagged output into JSON. Our tests showed the LLM performed best when asked for XML. Since downstream components in the application consume JSON, this converter bridges the gap.
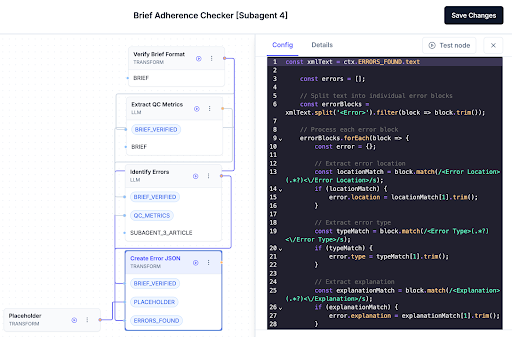
Why this method works: It reduces the strain on LLMs, makes outputs more predictable, and keeps workflows moving smoothly. We let AI do what it’s good at, and let deterministic logic handle the rest. That mix helps make systems both flexible and reliable.
3. Engineer your context, not just prompts
Problem: Building AI agents is about far more than prompting.
AI agents perform long-horizon tasks made up of multiple, interleaved messages: user inputs, reasoning steps, tool calls, tool responses, and intermediate outputs. Here, the model’s context window becomes prime real estate.
It’s not enough to craft a single well-written prompt. The entire conversation context has to be designed and managed dynamically, guiding the model’s attention toward what matters most, even as goals evolve.
Without that discipline, agents quickly drift: they lose planned steps, miss critical details, contradict earlier reasoning, rework completed tasks, fixate on irrelevant points, amplify previous AI errors, or simply run out of context space. These problems compound in multi-step workflows, where every extra message adds clutter and risk.
What we do: We manage the whole context and state.
Each Pepper AI agent uses multiple composable, project-specific prompt templates as building blocks, authored by our content experts specifically for that client. Every template is modular: segments can be added, removed, or recombined depending on the stage or use case. This keeps context predictably structured in a schema that LLMs can navigate easily. An added benefit of templates is that apps perform fairly consistently, no matter how skilled the user is at prompting.
Earlier, we described how we create specialised subagents for each key sub-task in a workflow. Context optimisation is a natural extension of that idea. Instead of crowding one agent’s context window with every asset and instruction, we split the job among several subagents, each focused and equipped for its part of the work.
Subagents pass only the necessary structured outputs between them. These are typically kept tight (a well-defined JSON, XML, or other schema), designed to strip away noise such as internal reasoning or tool-call history, while retaining essential signals like the agent’s key outputs, any assumptions made, or verification suggestions. This allows agents to interoperate cleanly without losing context or bloating the window.
Finally, as you saw in the Creative Builder example above, we keep context windows manageable through conditional context retrieval, piping in only the information directly relevant to the user’s current task and input parameters.
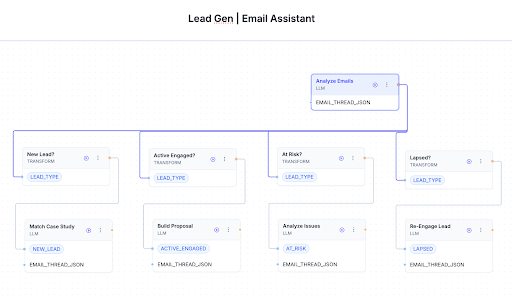
Example 1: In this simple lead-generation email workflow, an LLM analyst first classifies the lead. Branching conditions then programmatically route the task to the correct specialised subagent. Each subagent is armed with a distinct toolkit, assets, and instructions, so no single agent is burdened with the entire context needed for all possible scenarios.
Example 2: To optimise subagents’ context windows, our Google Ad Concept Generator workflow dynamically retrieves only relevant context and skills. This allows the subagents to handle lengthy Google ad specifications (guidelines for each ad format and campaign type) alongside large sets of brand assets (writing samples, branding guides, and website pages) without context bloat.
Why this method works: By modularising prompts, splitting work among subagents, structuring inter-agent handoffs cleanly, and retrieving only the context each task truly needs, we keep models flexible, focused, token-efficient, and less error-prone.
4. Expect inconsistency, and design for it
Problem: AI agents’ behaviour is notoriously hard to predict.
Because LLMs are stochastic by design, their outputs naturally vary, even when given identical inputs. Temperature settings and random sampling only amplify this. Two runs of the same prompt can produce different, even contradictory, responses and conclusions.
If your use case demands 100% consistency in outputs for a given input, AI alone might not be the right tool to solve your problem. AI is better suited for tasks where there’s some tolerance for variation and where outputs can be externally verified.
What we do: Design robust review systems to catch AI errors.
Pepper’s automated Content Audit system runs a tailored review on every AI-generated piece, using the client’s project brief as its ground truth. It checks for factual accuracy (more on that below), brand compliance, brief adherence, and more, automatically flagging anything that looks off.
Everything flagged by the audit flows to Pepper’s human editorial team. Editors review and correct all AI content, documenting common failures for our reference. Each project team maintains a live checklist of recurring AI errors and inconsistencies. Those insights loop back into the next version of the project’s AI agent, tightening quality over time.
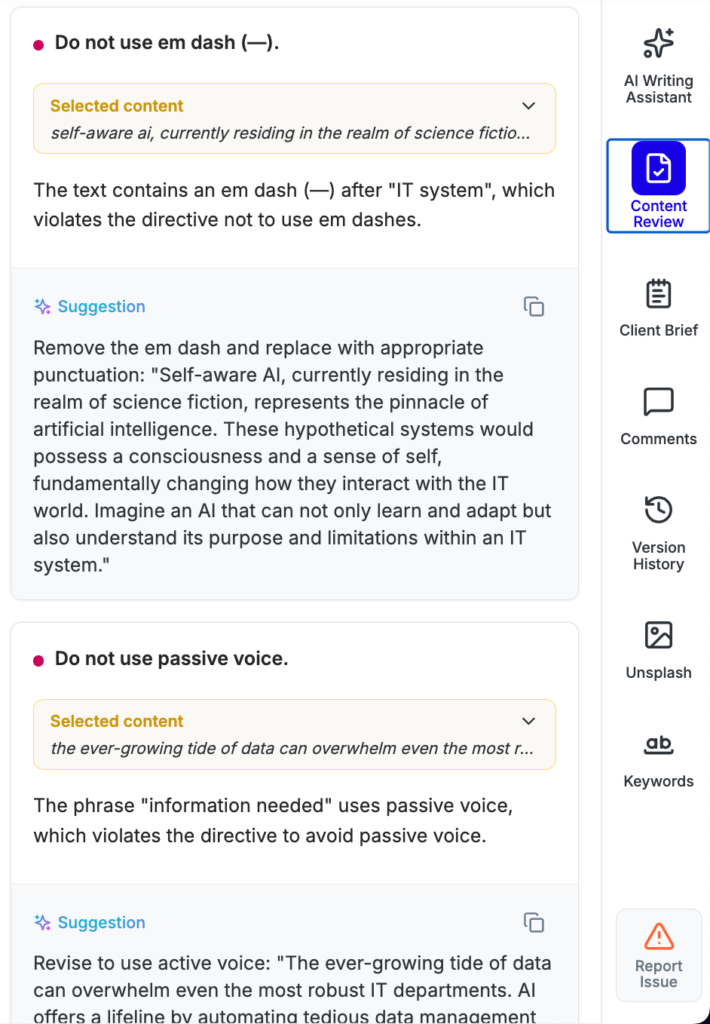
Why this method works:
Because inconsistency with AI is inevitable, the solution isn’t to fight it; it’s to contain the problem. Our automated audits catch systematic and mechanical errors at scale, while human reviewers handle the gray areas AI can’t judge. Together, they allow us to control quality and establish a continuous-improvement loop.
5. Ground everything to reduce hallucinations
Problem: AI has no world model or understanding of “truth”.
LLMs don’t know things. They only predict what token is likely to come next, based on statistical patterns in their training data. They have no sense of truth-value, cause-and-effect, or the difference between fact and fiction. For a model, everything it says is technically a hallucination; humans only use that term when an output happens to be factually untrue.
So every AI application must be built to minimise hallucination, since it cannot really be eliminated. If a model operates without sufficient grounding, it inevitably fills data gaps with confident guesses, in a bid to complete the expected patterns.
What we do: We link every agent to multiple sources of ground truth and research data.
No Pepper AI output is left without grounding. Each agent’s context is enriched with relevant information, drawn from a variety of verified, relevant, and up-to-date sources specific to the client’s domain. Directly providing the model with the task-related facts it needs is a straightforward way to reduce the chances of fabricated claims.
Our workflows pull data from several layers of trusted input:
- The human user’s research, provided at runtime
- Real-time web retrieval from filtered, client-approved sources
- Searches within brand knowledge bases, if assets are available
- Internal brand research curated by Pepper’s team
- External connectors (like Semrush for SEO and performance data)
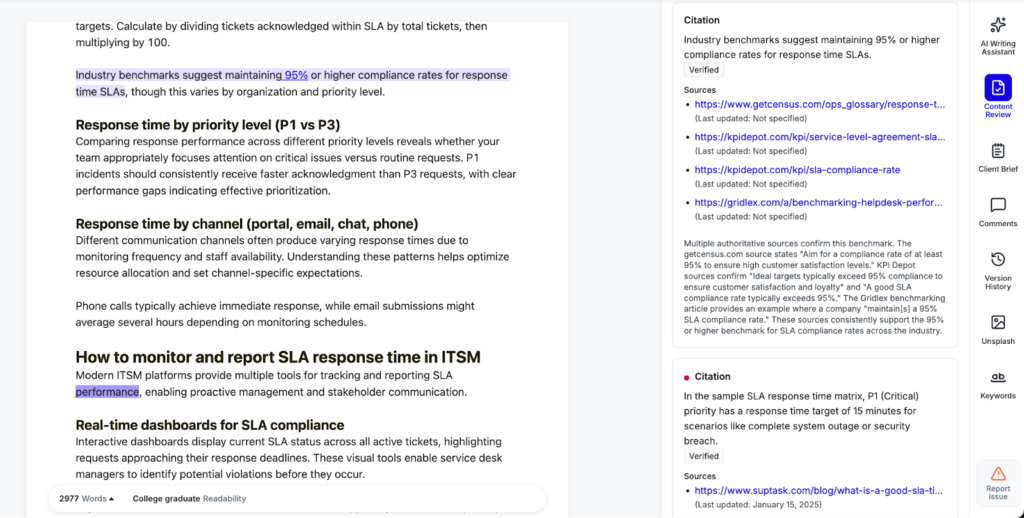
Every grounded output includes source citations, for manual cross-checks.
Once the content is drafted, our automated fact-checker extracts all claims and searches approved sources for validation; anything unverified is flagged for human review.
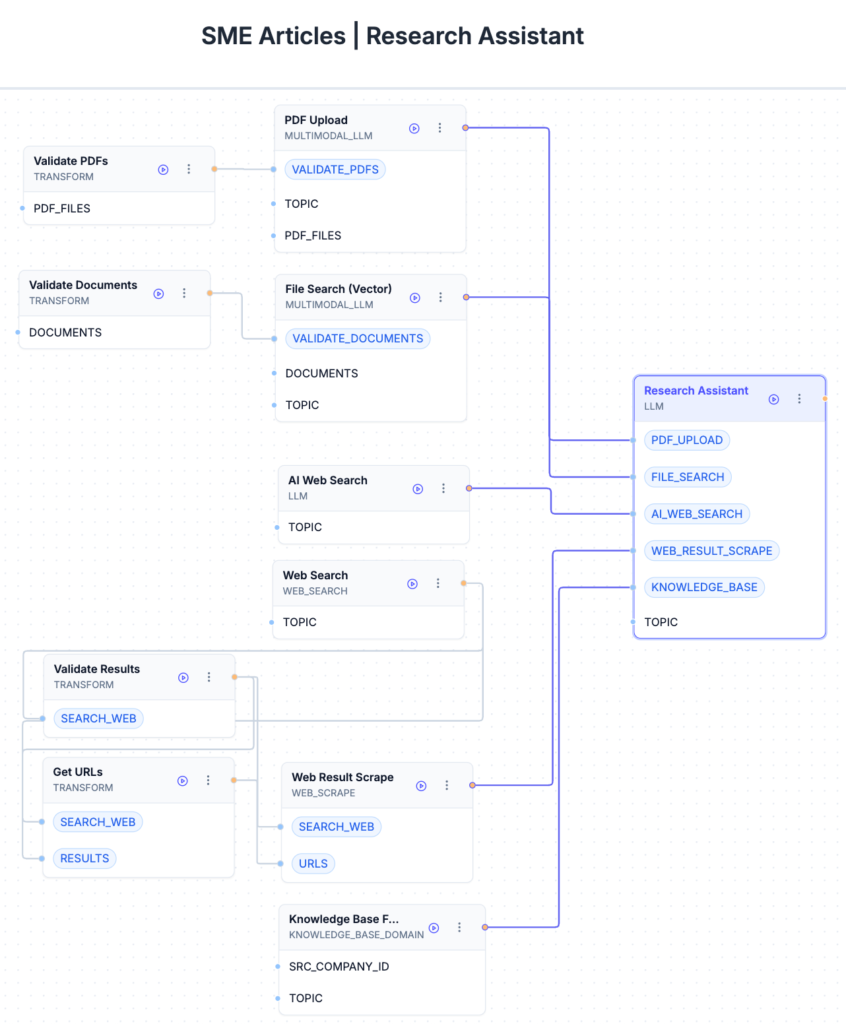
Example 1: The Research Assistant agent has access to combined data from multiple channels: (a) LLM subagents analyse uploaded PDFs, read user-provided files, and perform AI-assisted web searches. (b) Programmatic steps run standard web searches and scrape result pages for additional context. (c) A separate step queries the brand’s internal Knowledge Base on Pepper. All this information is then consolidated and cited within the agent’s output, so readers can trace every fact back to a source.
Example 2: Pepper’s Content Audit system includes a dedicated fact-checking layer that extracts each claim from the AI output and looks for confirmation within approved sources. If no validation is found, or if conflicting evidence appears, the claim is flagged for manual review before publication.
Why this method works:
When the context contains strong grounding data that’s highly relevant to the task at hand, models get the chance to directly retrieve claims, rather than rely on patterns learned in pre-training. This reduces the agent’s chances of needing to invent details to fill blanks.
6. Put a highly skilled human in the loop
Problem: AI agents aren’t yet capable of being wholly autonomous.
Despite the amazing advances reasoning models have made, AI agents still aren’t autonomous. They tend to derail mid-task, make false assumptions, form incorrect plans, lose track of steps, skip clarifications, hallucinate facts, or fail to verify their own outputs.
These issues multiply when users can’t see the reasoning process or intervene to steer it. There’s plenty of promising research into automated self-correction, but in practice, many of these problems can be prevented more simply and reliably by keeping a human in the loop, wherever scale allows.
What we do: We put trained AI content experts at the helm.
Every Pepper workflow begins with high-quality human input, from trained creators who understand both the brief and the model’s limitations. The golden rule, as always, is: garbage in, garbage out.
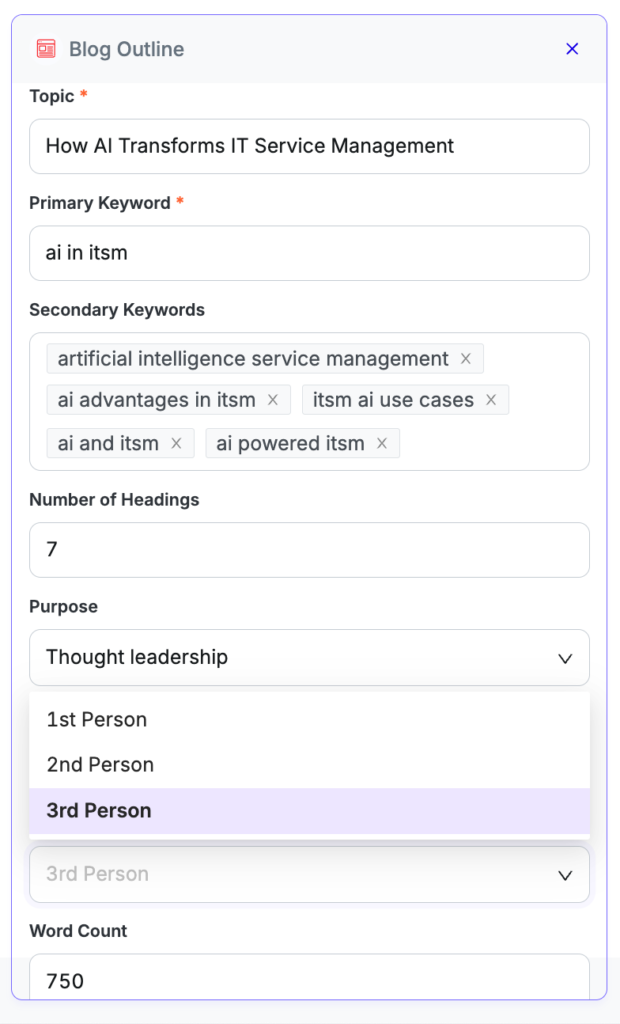
We validate every input before it reaches the model. AI agents on Nymbus receive inputs via forms, which enforce strict rules: app authors can define the form fields, allowed values, formats, minimum/maximum lengths, and so on. In sensitive workflows, an LLM verifier might check user entries first, flagging unclear or non-compliant inputs and asking for corrections. This ensures our workflows receive usable inputs that are largely aligned with test scenarios and what the agents “expect.
Example: This input form uses a few of Pepper’s basic input field types: Short text, tags, numbers, and single-select dropdown. Nymbus offers several other field types too, each with input validation configured by the app author.
Human oversight doesn’t stop at the input stage. For complex, multi-agent flows, we build breakpoints where the human must review the content before moving forward to the next stage. For instance, a topic literature review produced by an AI Researcher agent will require a human editor’s manual approval and handover to a Content Creator agent for outline generation.
Our human teams are AI-trained domain specialists, equipped with detailed checklists that reflect the specific error types observed in each project. These checklists evolve continuously as we learn from the data.
Why this method works: No LLM, however capable, matches human judgment in context, nuance, and accountability. Skilled humans catch what models miss and keep the system honest. By embedding trained reviewers and structured checkpoints in the work process, we maintain both speed and accuracy.
7. Let domain experts help build AI agents
Problem: AI app builders don’t grasp users’ real problems.
People who live the work understand their domain, but rarely have the technical skills to build AI apps. Conversely, AI engineers know how to configure models and workflows, but often don’t understand the nuances of how tasks actually get done.
The result is a familiar kind of failure: technically sophisticated agents that feel disconnected from users’ real needs. Only domain experts really grasp how users think through problems, make decisions, and go about their everyday business.
What we do: Pepper’s AI apps are co-authored by content specialists.
Our AI team includes both engineers and content and editorial specialists. Every AI app begins with an exhaustive internal project brief that documents the client’s full creative requirements, references, targets, edge cases, brand guidelines, and so on. The content experts curating the brief have a hands-on end-to-end grasp of the human creation process. They know where AI can really help, where it’s ineffective, and how to draw the line between the two.
This joint authorship means each AI application is designed with clear boundaries. Early on, we demarcate which tasks the agent can handle autonomously and which require human judgment or input.
Before release, every tool goes through a structured testing protocol and must be approved by the editorial or quality team that owns that client project. Only then does it reach end users.
Why this method works: When domain experts co-design with engineers, agents reflect the actual shape of the work they’re meant to support. That alignment produces AI tools that fit naturally into day-to-day content creation, amplifying human creators’ unique skills.
8. Integrate AI with your daily work tools
Problem: Many AI projects fail because the tools live in isolation.
When AI sits outside the systems people actually use, floating in a separate dashboard or external app, it becomes another disconnected experiment. Users have to copy-paste data in and out, switch contexts, or work around missing integrations. Eventually, they stop using it.
What we do: We bring AI to where people already work.
Pepper’s AI tools are deeply embedded in Pepper Docs, our native document editor, and tied directly to our operations backend. This means creators don’t have to learn a new workflow or export files between systems. They create and refine content within a single familiar workspace, with AI assistance at their fingertips.
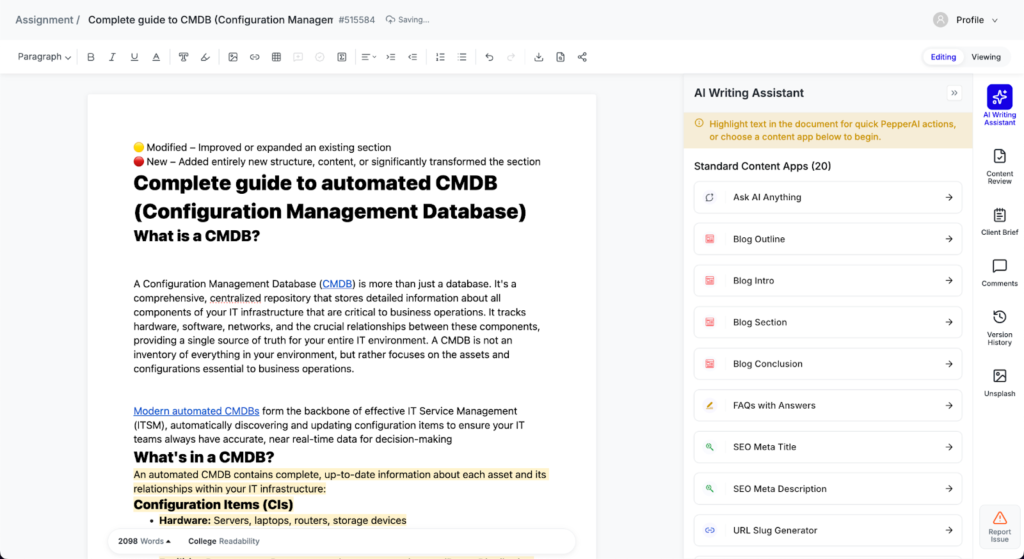
Why this method works: Adoption depends on proximity. Making AI a seamless part of everyday tools and workflows, so that outputs flow directly into production systems, gives your apps their best shot at keeping users on board.
9. Iterate fast!
Problem: Slow feedback loops kill many promising AI projects.
No AI battle plan survives the first bullet. Because LLMs are so sensitive to context and inputs, a model’s behaviour can shift dramatically across real-world use scenarios. You can’t predict every edge case in advance – no matter how much testing you do. That’s why every AI app needs constant, hands-on tuning based on how users actually work with it.
Without rapid iteration cycles, friction points become deal-breakers. Users start building their own workarounds or drop the tool entirely when it stops saving them time.
What we do: Pepper’s dedicated AI team keeps iteration tight and fast.
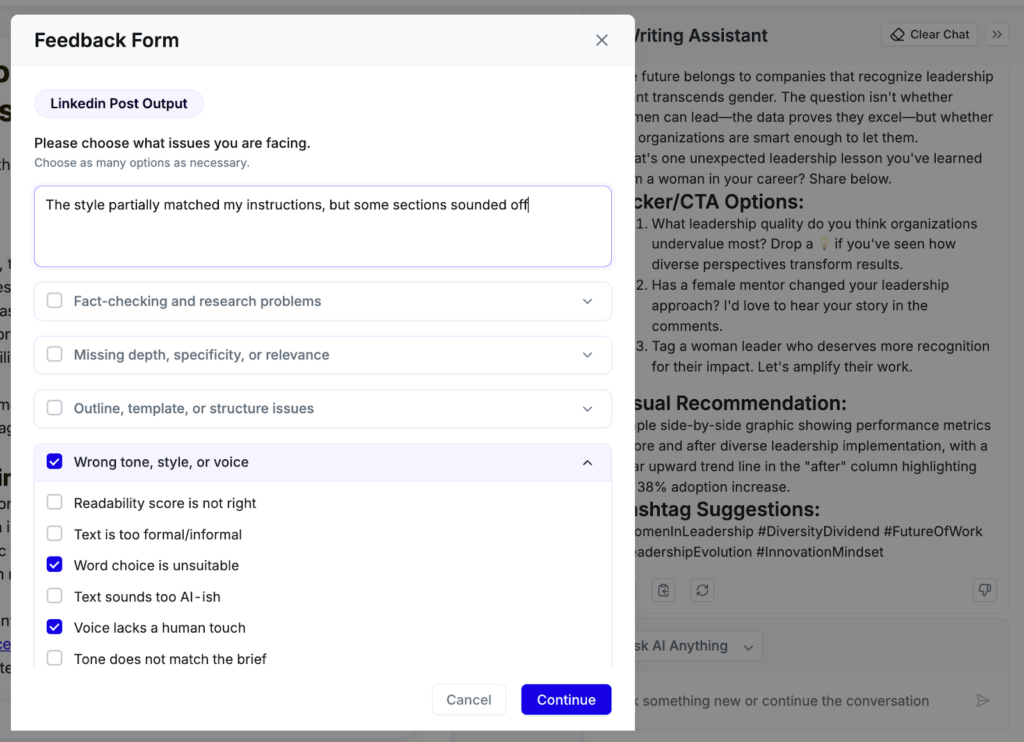
Pepper’s AI team monitors app usage daily and rolls out fixes or improvements within a few days of user feedback.
A built-in AI feedback feature lets users flag problematic outputs right where they occur. Each flag triggers a backend alert, giving our team clear visibility into what failed, why, and under what conditions.
This feedback loop keeps our AI tools alive and evolving in real time, instead of becoming static projects that rapidly age out.
Why this method works: Because AI behaviour changes fast, iteration speed on AI apps is everything. Continuous feedback and quick updates keep tools aligned with real workflows and prevent user frustration, turning each app run into a live test.
Closing: what good content agent design looks like
We built Nymbus and our operational model around a simple proposition: you don’t fix LLM brittleness with a fancier prompt. You fix it with stronger systems.
Specialised agent clusters, hybrid programmatic/stochastic workflows, rigorous context and prompt engineering, automated content review systems, solid ground-truthing, numerous human checkpoints, co-design with domain experts, tight product integration, and rapid feedback-based iteration have driven dependable AI outcomes for Pepper at scale. Those practices let our agents move out of pilots and into everyday content work.
Pepper’s AI-first content and editorial experts, and the tooling they operate, have turned agentic AI from a risk into a repeatable capability. We now drive some of Pepper’s biggest projects using multi-stage, multi-agent, human-in-the-loop workflows that handle our most complex client briefs and use cases.
If you’re planning agentic content systems, here are our top three takeaways: start with a well-defined scope, keep context management tight, and let AI work in tandem with deterministic logic and human talent.
Latest Blogs
This blog focuses on 12 of India’s top content writing services.
According to the Content Marketing Institute, one of the most effective ways to promote a business is via good content. At least half of all marketers either are or are planning to use content to reach their customers.
Get your hands on the latest news!



